The propensity score is defined as the conditional probability of receiving treatment given observed covariates (Rosenbaum and Rubin 1983):
\[
e(X) = P(T = 1 | X)
\]
where:
\(T \in \{0, 1\}\) is the binary treatment indicator
\(X\) is a vector of pre-treatment covariates
The Balancing Property
Rosenbaum and Rubin (1983) proved that conditioning on the propensity score is sufficient to remove bias from observed confounders:
\[
(Y^1, Y^0) \perp T | e(X)
\]
This remarkable result reduces the dimensionality of the matching problem. Instead of matching on all \(p\) covariates in \(X\), we can match on the single scalar \(e(X)\).
Why this works:
The propensity score is a balancing score: At each value \(e(X) = e_0\), the distribution of covariates \(X\) is the same in the treated and control groups.
Formally: \[
X \perp T | e(X)
\]
Estimating the Propensity Score
Logistic Regression
The most common approach estimates \(e(X)\) using logistic regression:
This yields: \[
\hat{e}(X_i) = \frac{1}{1 + \exp(-X_i^\top \hat{\beta})}
\]
Alternative Methods
For more flexible functional forms:
LASSO Regularization: Applies \(L1\) penalty to linear models to perform automatic variable selection, shrinking coefficients of irrelevant predictors to zero while estimating treatment probabilities with reduced dimensionality.
Generalized Boosted Models (GBM): Iteratively builds an ensemble of weak learners (typically trees) to minimize prediction error, effectively capturing nonlinear relationships and interactions in treatment assignment.
Random Forests: Aggregates predictions from multiple decision trees trained on random subsets of data and features, providing robust propensity score estimation with built-in feature importance measures.
Neural Networks: Uses interconnected layers of nonlinear activation functions to learn complex, high-dimensional relationships between covariates and treatment assignment, particularly useful with large covariate sets.
Matching Algorithms
There are several practical matching algorithims you can use to construct match propensity scores along.
1. Nearest Neighbor Matching
Match each treated unit to the \(k\) closest control units based on propensity score distance:
\[
d(i, j) = |e(X_i) - e(X_j)|
\]
With replacement: Control units can be matched multiple times Without replacement: Each control used at most once
2. Caliper Matching
Impose a maximum distance threshold \(c > 0\) (the caliper). Only considers matches if:
\[
|e(X_i) - e(X_j)| < c
\]
Common choice: \(c = 0.25 \times \text{SD}(\text{logit}(e(X)))\)
3. Kernel Matching
Weighted average of all controls, with weights inversely proportional to distance:
where \(K(\cdot)\) is a kernel function and \(h\) is the bandwidth.
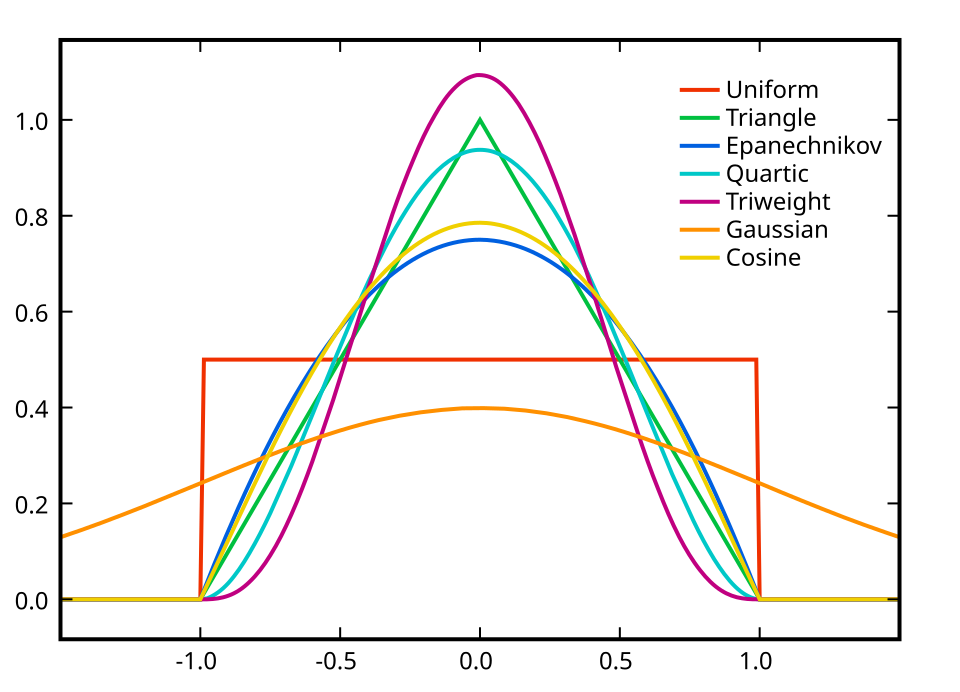
Kernel Selection
There are several types of kernels to select from. The most common selection is the Epanechnikov (parabolic) kernel. Below I provide a visualization of these kernels as well as a comparision across these kernels.
Kernel
Support
\(K(u)\)
Efficiency (relative to Epanechnikov)
Uniform (Rectangular)
\(\|u\| \leq 1\)
\(\frac{1}{2}\)
92.9%
Triangular
\(\|u\| \leq 1\)
\(1 - \|u\|\)
98.6%
Epanechnikov (Parabolic)
\(\|u\| \leq 1\)
\(\frac{3}{4}(1 - u^2)\)
100%
Quartic (Biweight)
\(\|u\| \leq 1\)
\(\frac{15}{16}(1 - u^2)^2\)
99.4%
Triweight
\(\|u\| \leq 1\)
\(\frac{35}{32}(1 - u^2)^3\)
98.7%
Tricube
\(\|u\| \leq 1\)
\(\frac{70}{81}(1 - \|u\|^3)^3\)
99.8%
Gaussian
All \(u\)
\(\frac{1}{\sqrt{2\pi}}e^{-\frac{1}{2}u^2}\)
95.1%
Cosine
\(\|u\| \leq 1\)
\(\frac{\pi}{4}\cos(\frac{\pi}{2}u)\)
99.9%
Logistic
All \(u\)
\(\frac{1}{e^u + 2 + e^{-u}}\)
88.7%
Sigmoid
All \(u\)
\(\frac{2}{\pi(e^u + e^{-u})}\)
84.3%
Optimal Bandwidth Selection
The choice of bandwidth \(h\) is critical for kernel matching, as it controls the trade-off between bias and variance. The most common optimality criterion is the Mean Integrated Squared Error (MISE):
Since \(R(f'')\) is unknown in practice, the Rule of Thumb estimator provides a practical solution by assuming the underlying density is approximately normal:
where IQR is the interquartile range. This modification improves performance for skewed or heavy-tailed distributions. The Rule of Thumb is the default bandwidth selector in most statistical packages due to its simplicity and reasonable performance, though it may oversmooth bimodal or multimodal distributions.
Estimation
As an example, we will explore the lalonde data set that comes with the MatchIt R package. This is data from the National Supported Work Demonstration used by Dehejia and Wahba (1999). The outcome of interest is 1978 real wages re78.
“We use data from Lalonde’s evaluation of nonexperimental methods that combine the treated units from a randomized evaluation of the NSW with nonexperimental comparison units drawn from survey datasets.”
The variables in this data are:
treat: The treatment assignment indicator is the first variable of the data frame: treatment (1 = treated; 0 = control).
age, measured in years;
education, measured in years;
black, indicating race (1 if black, 0 otherwise);
hispanic, indicating race (1 if Hispanic, 0 otherwise);
married, indicating marital status (1 if married, 0 otherwise);
nodegree, indicating high school diploma (1 if no degree, 0 otherwise);
from causalinference import CausalModelimport pandas as pd# Load datadata = pd.read_csv('lalonde.csv')# Prepare dataY = data['re78'].valuesD = data['treat'].values X = data[['age', 'educ', 'race', 'married','nodegree', 're74', 're75']].values# Fit modelcausal = CausalModel(Y, D, X)# Estimate propensity scorescausal.est_propensity_s()# Match with calipercausal.est_via_matching(matches =1, bias_adj =True)# Resultsprint(causal.estimates)
* Load dataimport delimited "lalonde.csv", clearegen race1 = group(race)* Estimate propensity scorelogit treat age educ race1 married nodegree re74 re75* Predict propensity scorespredict pscore, pr* Nearest neighbor matching with caliperpsmatch2 treat, pscore(pscore) outcome(re78) caliper(0.25) ate* Check balancepstest age educ1 race married nodegree re74 re75, /// treated(treat) pscore(pscore)
Critiques of PSM
Despite its intuitive appeal, King and Nielsen (2019) show that propensity score matching often fails to achieve adequate covariate balance and can even increase imbalance compared to simpler methods.
Key Problems:
Paradox of PSM: Equal propensity scores do not guarantee similar covariates
\[
e(X_i) = e(X_j) \not\Rightarrow X_i = X_j
\]
But: \[
X_i = X_j \Rightarrow e(X_i) = e(X_j)
\]
Model dependence: Small changes in propensity score specification can dramatically change matches
Inefficiency: Discarding unmatched units reduces sample size unnecessarily
Approximation stochasticity: The quality of matches varies randomly based on the specific sample
Potential Better Alternatives
Covariate matching (Mahalanobis distance, CEM)
Inverse probability weighting (IPW)
Doubly robust estimators
Entropy balancing
Common Pitfalls
Including post-treatment variables in propensity score model
Ignoring lack of common support
Using p-values to assess balance (conflates sample size with balance)
Not checking covariate balance after matching
Treating estimated propensity scores as known
Recommended Workflow
Specify covariates based on domain knowledge (include all confounders)
Estimate propensity scores
Check overlap (common support)
Perform matching
Assess balance (standardized mean differences, variance ratios)
If imbalance remains: refine model or try different matching method
Estimate treatment effect on matched sample
Sensitivity analysis for potential hidden bias
References
Dehejia, Rajeev, and Sadek Wahba. 1999. “Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs.”Journal of the American Statistical Association 94: 1053–62.
King, Gary, and Richard Nielsen. 2019. “Why Propensity Scores Should Not Be Used for Matching.”Political Analysis 27 (4): 435–54. https://doi.org/10.1017/pan.2019.11.
Rosenbaum, Paul R., and Donald B. Rubin. 1983. “The Central Role of the Propensity Score in Observational Studies for Causal Effects.”Biometrika 70 (1): 41–55. https://doi.org/10.1093/biomet/70.1.41.